ツリーから項目を選択し、項目に複数のページがあった場合は最後まで送りながらスクレイピングしていく感じで作成したい。
ループをどうやって定義していけばいいか。
スクレイピングで、ページ送りしながら表をコピーする。
Contents
ツリーを順番にクリックしていく
とりあえず、URL でできる範囲はなるべくURL で解決します(ツリーの種類指定など)。
また、閉じたツリーの展開などは面倒なので手動でやっておきます。
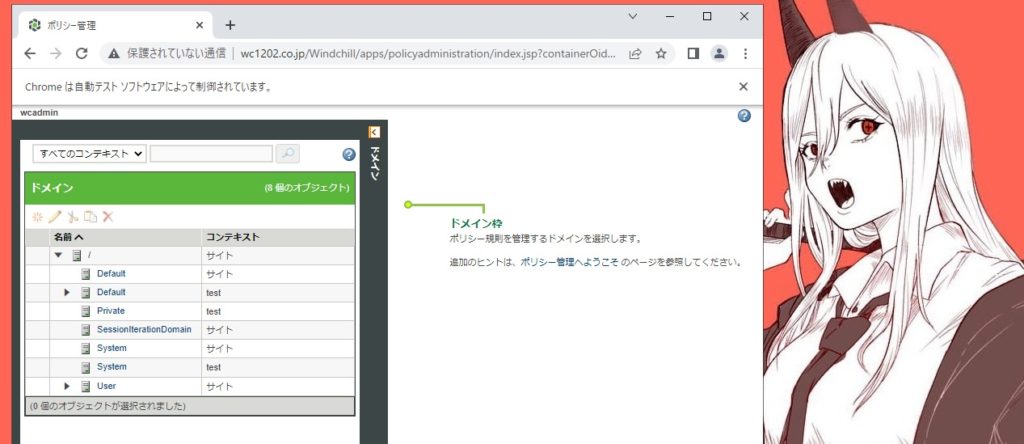
ツリー項目を順番に選択
ツリーは手動で展開状態にしておきます。
項目には、「domainTableLink…」というユニークなクラス名があったので、これをキーワードにspan → a ルートで取得することにしました。
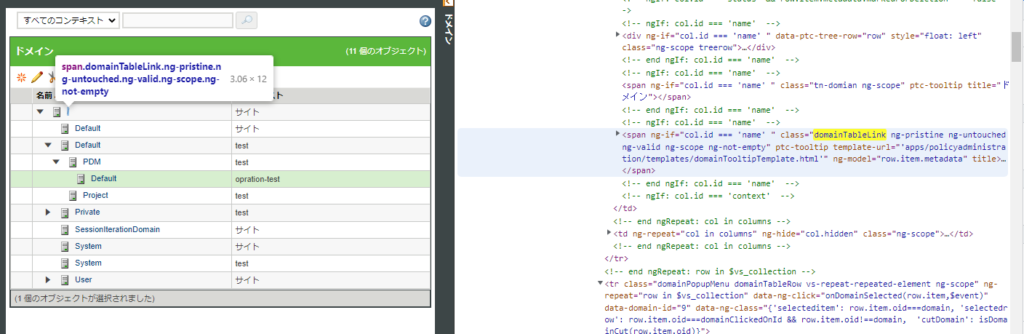
span タグの中にお目当ての a タグがある感じ。
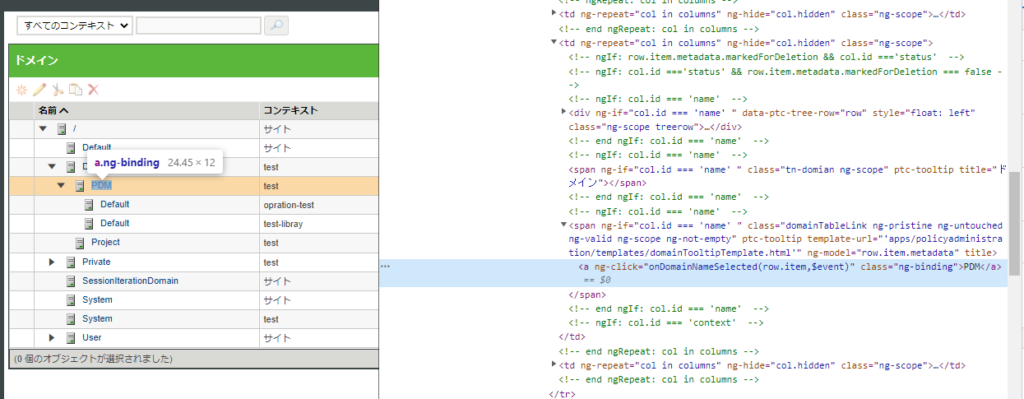
ツリーの取得はこんなかんじで。
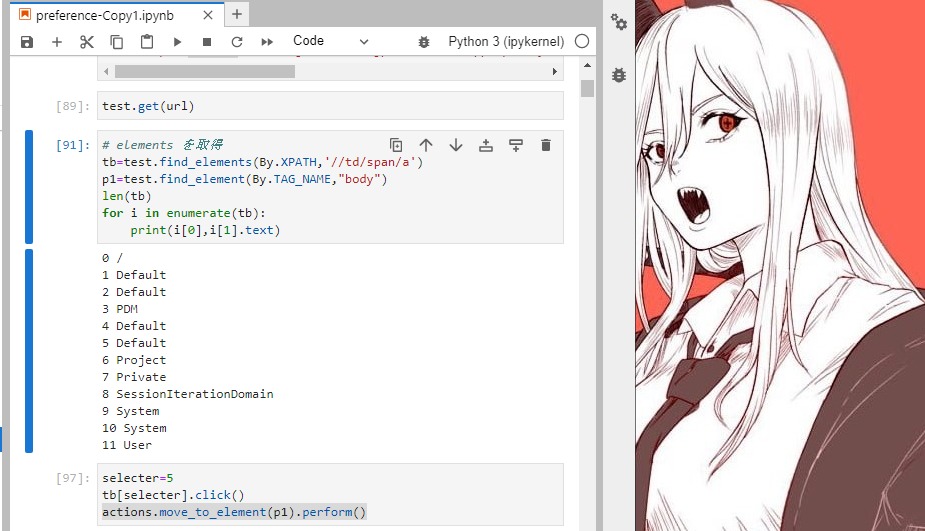
マウスオーバーしたい
ツリーをクリックすると、ポップアップが発生。
このポップアップにフォーカスが移ってしまうようで、あとの処理が軒並みエラーになる。
対策として、クリックした後にマウスオーバーさせてポップアップを消すという処理を入れました。
from selenium.webdriver.common.action_chains import ActionChains
actions=ActionChains(test)
actions.move_to_element(p1).perform()ActionChains のインポートが必要。
テーブル読み込み
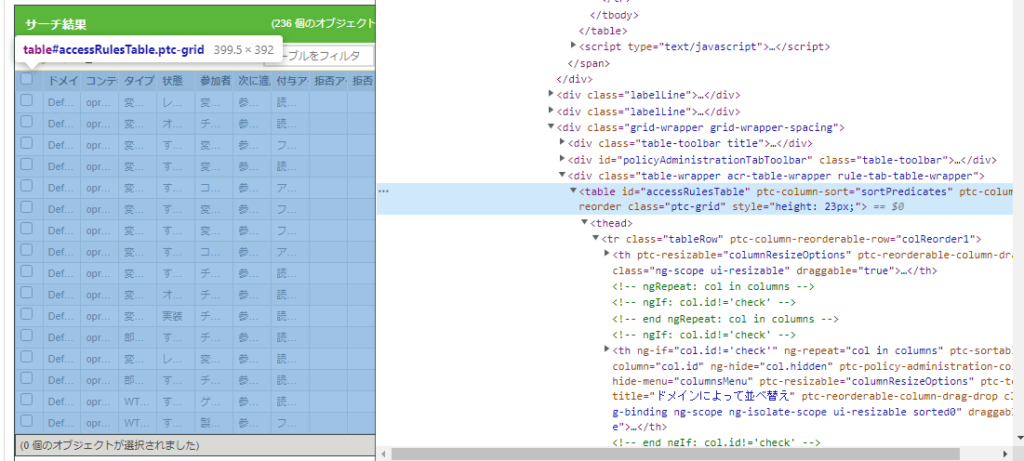
ココもXPATH できれいに取れました。
tb2=test.find_elements(By.XPATH,'//table[@id="accessRulesTable"]/tbody/tr/td')
for j in enumerate(tb2):
print(j[0],j[1].tag_name,j[1].text)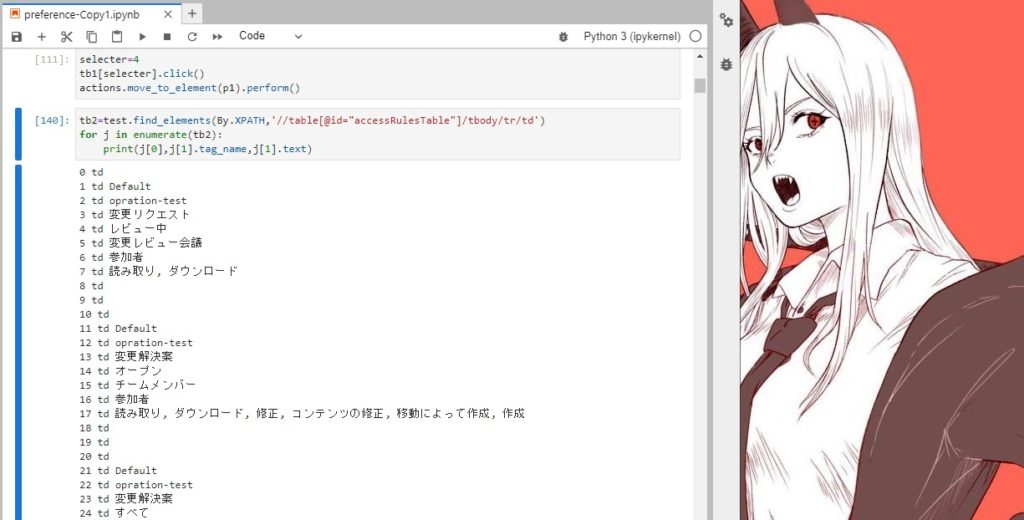
今更ですが、find で取得したのもは、指定した要素のみを集めたものなので、
ざっくり全体を取得してデータの内容をみてから考えるとかできないんだなーと気付く。
ページ送りボタンの取得
送りのボタンもXPATH でざっくっと取得。
クリックもきた。
(li タグに[12] を指定するとクリックができなかった。)
xpath3='//*[@id="policyAdministration_tabs"]/div/div/div/div/div/div/div/ul/li'
tb3=test.find_elements(By.XPATH,xpath3)
for j in enumerate(tb3):
print(j[0],j[1].tag_name,j[1].text)
tb3[12].click()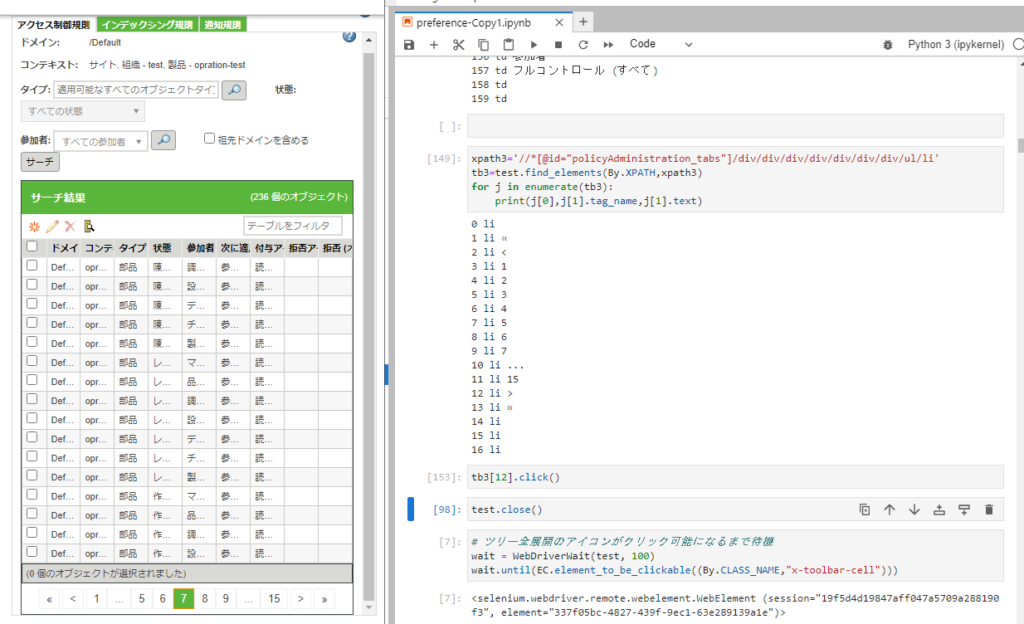
ループの作成
後はこの要素3つを組み合わせてループさせれば一発で取得できるぜ。
テーブルを10 個ずつまとめないといけないと気付く。
そして、先に行で取得して分解すればいいと気付く。
xpath2='//table[@id="accessRulesTable"]/tbody/tr'
tb2=test.find_elements(By.XPATH,xpath2)
tb2td=tb2[0].find_elements(By.TAG_NAME,"td")
for a in enumerate(tb2td):
print(a[0],a[1].text)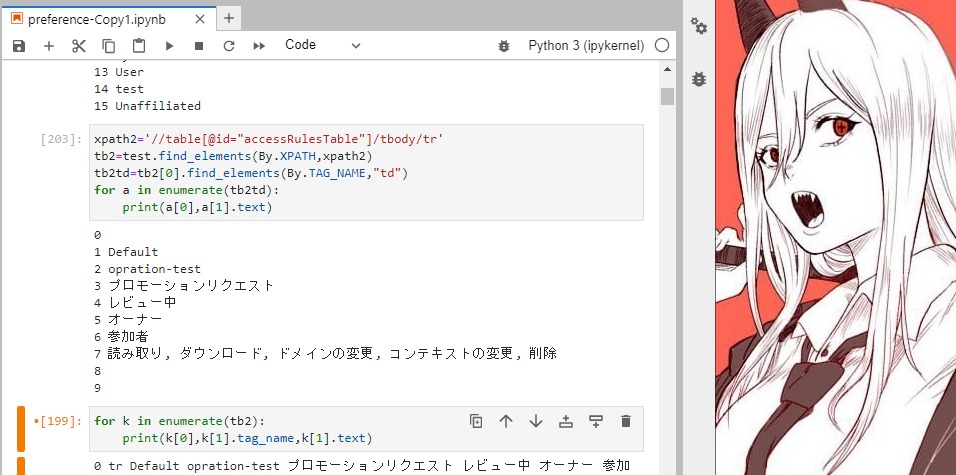
ちょっと、ややこしくなってきたので関数を導入する。
関数の作成
ちょっと複雑に入り組んできたので、関数で処理をまとめる。
関数にした方がわかりやすいし、デバックもしやすい。
Pythin の文法ってループ関連もそうだけど、インデントでまとめるのってシンプルでイイです。
諸 ゲットする関数
これはタグをゲットする時の関数。
引数で処理を切り替えてます。この辺りって好みの問題ですね。
def getp(selecter):
##### domain tree ######
if selecter == "domaintree":
# elements を取得
r=test.find_elements(By.XPATH,'//*[@class="domainTableLink ng-pristine ng-untouched ng-valid ng-scope ng-not-empty"]/a')
##### body ######
elif selecter == "body":
r=test.find_element(By.TAG_NAME,"body")
##### botton slider ######
elif selecter == "nextbtns":
r=test.find_elements(By.XPATH,'//ul[@class="pagination ng-scope"]/li')
##### botton ######
elif selecter == "nextbtn":
r=getp("nextbtns")
if len(r)!=0:
## get key next
for i in enumerate(r):
if i[1].text == ">":
r = i[1]
break
else:
r="no_pages"
##### botton 2 ######
elif selecter == "frontbtn":
r=getp("nextbtns")
if len(r)!=0:
## get key next
for i in enumerate(r):
if i[1].text == "«":
r = i[1]
break
else:
r="no_pages"
##### how many bottons ######
elif selecter == "nextbtnMax":
r=getp("nextbtns")
if len(r)!=0:
## get key next
for i in enumerate(r):
if i[1].text == ">":
r = int(r[i[0]-1].text)
else:
r=1
##### ACL Table ######
elif selecter == "acltableRow":
### get ACL table
r=test.find_elements(By.XPATH,'//table[@id="accessRulesTable"]/tbody/tr')
time.sleep(1)
##### OTHERS ######
else:
r="ERROR : not find such a keyword"
return rリスト作成(ツリー)
ツリーの指定した区間だけをリストにする関数。
def ab(obj,a,b):
flag = 0
r = list()
for i in obj:
if i.text == a:
flag = 1
continue
if i.text == b:
break
if flag == 1:
r.append(i)
return rテーブル行の分解
テーブルから行を取得する。
ページ送りがあるかどうかの判定もしています。
(ページ数を取得して、繰り返すという単純なもの。)
def gettb():
p("start gettb")
page_max=getp("nextbtnMax")
nextbtn=getp("nextbtn")
r =list()
if nextbtn != "no_pages":
for k in range(page_max):
r = r +acltableCell(getp("acltableRow"))
p(acltableCell(getp("acltableRow")))
nextbtn.click()
time.sleep(0.5)
else:
r = r +acltableCell(getp("acltableRow"))
p(acltableCell(getp("acltableRow")))
return rテーブルの行から、セルを取得する。
def acltableCell(row):
r = list()
for i in row:
sub_strings=list()
tmp=i.find_elements(By.TAG_NAME,"td")
for j in tmp:
sub_strings.append(j.text)
r.append(sub_strings)
return r本体はこんな感じです。
tree = ab(getp("domaintree"),"PDM","Project")
res=list()
fini=""
for i in tree:
p(i.text)
i.click()
act.move_to_element(getp("body")).perform()
time.sleep(2)
frtbtn=getp("frontbtn")
if frtbtn != "no_pages":
frtbtn.click()
res = res +gettb()
for j in res:
fini=fini +sep.join(j) +"\n"
p("############################################")
p(fini)
参考:
https://www.javadrive.jp/python/jupyter-notebook/index5.html
https://note.nkmk.me/python-str-num-conversion/