フツーの表なら矩形選択してからコピペで一括コピーできるんですけど、ツリー的な形式に装飾してあるような一覧だと、うまくコピペできない。
ペーストした時に、行がずれたり、飛んだりしてしまう。
少しくらいなら、編集しながら頑張れるけど、コピーしたい値の数が多いと無理くてしんどい。
日が暮れる程度ならまだ許容できるけど場合によっては数日かかってしまう。
WEBページ「ツリー型リスト」を一括でコピぺしたい。
WEBページの一覧がうまくコピーできない。
フツーの例
こういった「フツーの表」だったらフツーにコピペできる。
選択してコピー、エクセルにペースト。
想定通りにコピペできています。
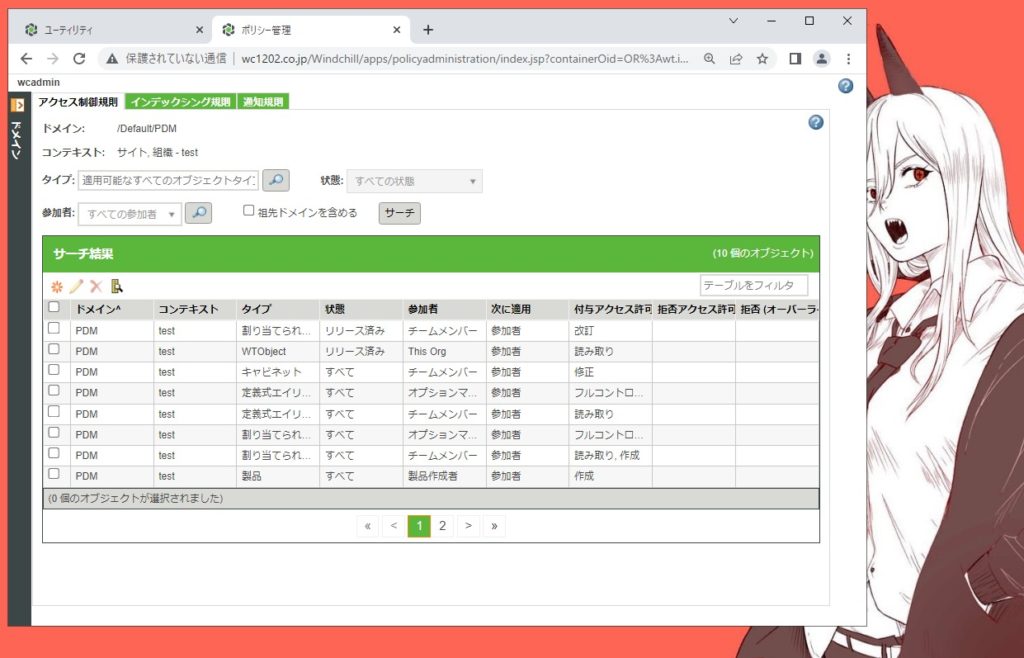
うまくできない例
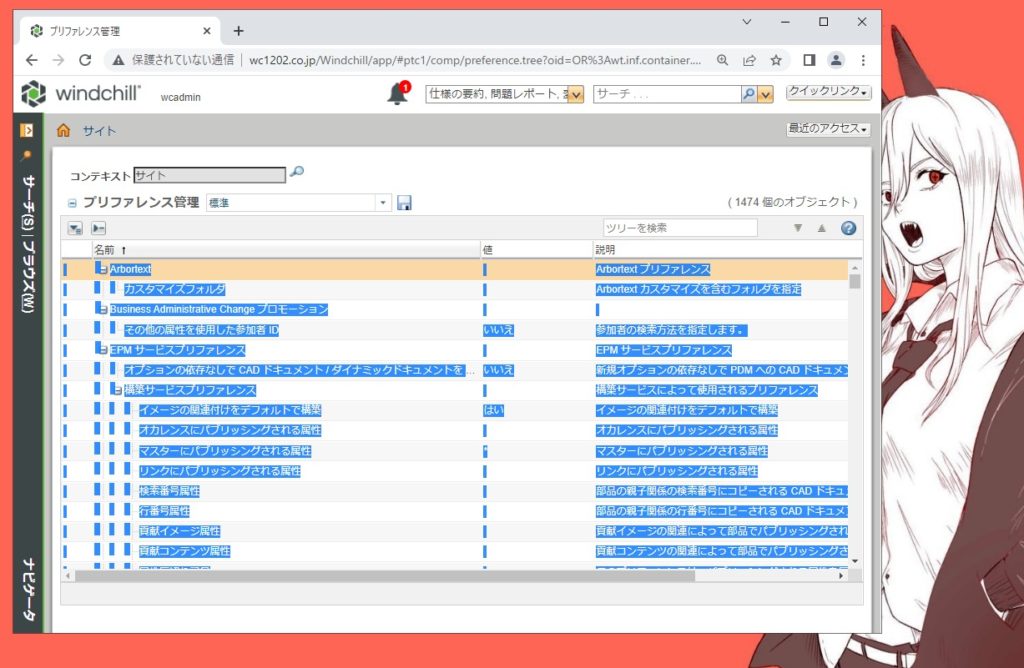
こういうツリー構造だと、行がずれてしまったりしてうまくいかない。
しかも、数が多くスクロールさせながら全部コピーするのはしんどい。(ちなみに1500項目程度あって、頑張っても2日くらいかかる。)
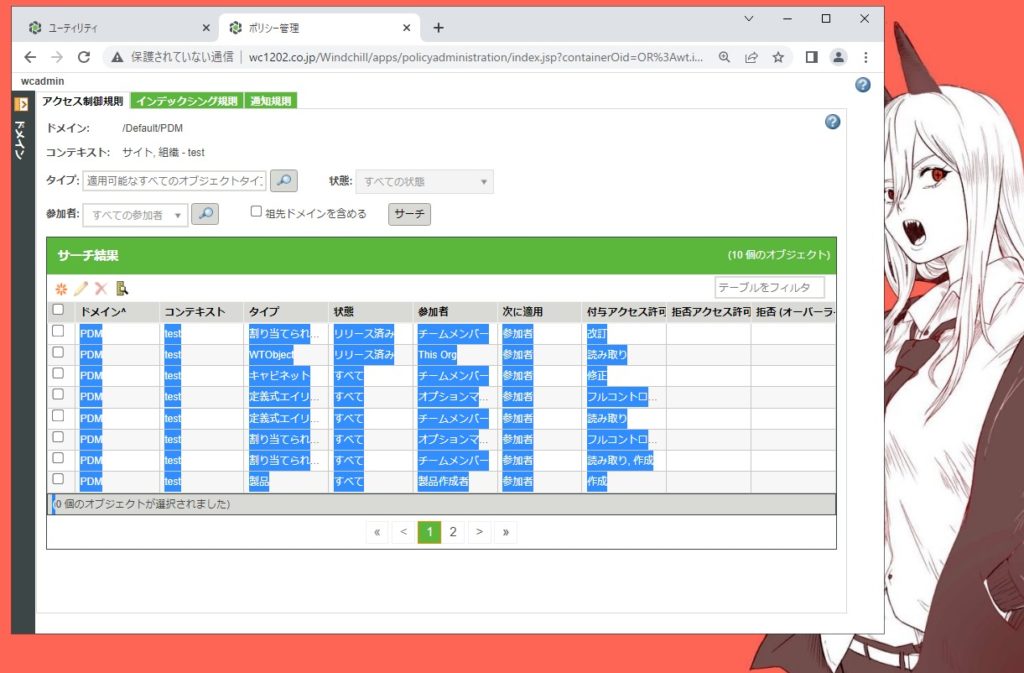
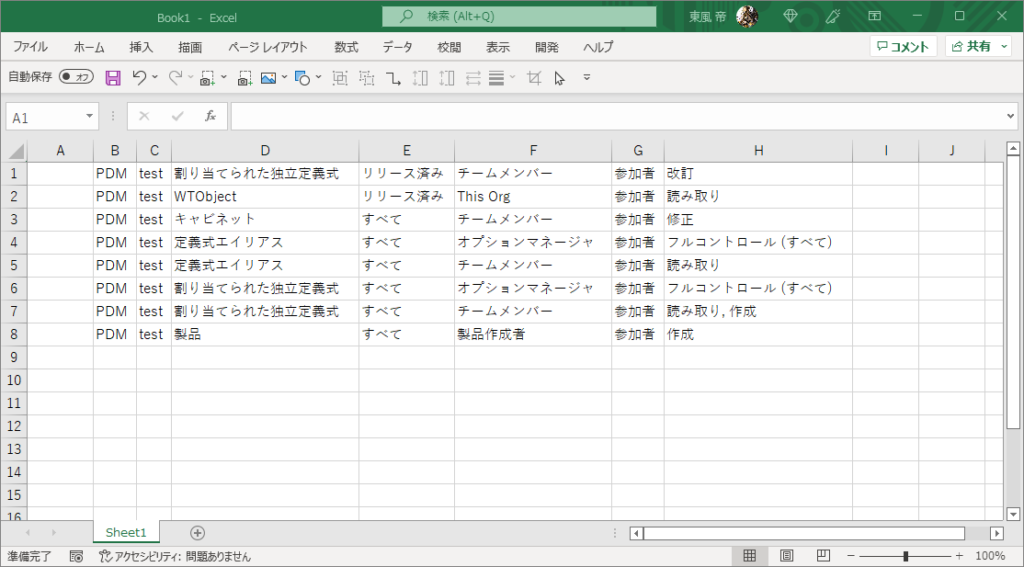
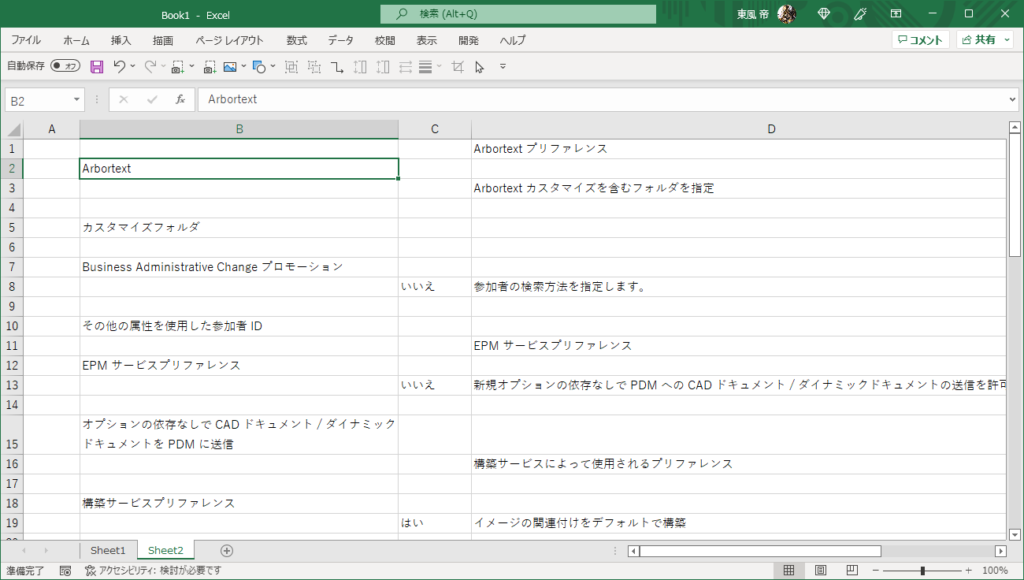
選択してコピー、エクセルにペーストしてみる。
行がズレてしまう。
あと、余計な改行も含まれてしまう。
というわけで、スクレイピングを使って、WEB ページを解析し、データを成形したいと思う。
WEBページ解析 環境の導入
使用したのはPython とJupyter Notebook です。
(ちなみにターゲットはWindchill という、PTC 製のPDM システムです。)
- Python 3.11.0
- selenium 4.6.0
- jupyterlab 3.5.0
- Chrome バージョン: 107.0.5304.62(Official Build) (64 ビット)
Python をインストール
Downloads をクリックして、python 最新版をダウンロード。
Install Now を選択して、インストール。
「Add python.exe to PATH」にチェックを入れておきました。PATH に入れておけば何かと便利ですよね。
「Disable path length limit」をクリックして実施、「Close」をクリックして閉じる。
「Disable path length limit」については下記を参考。
「Jupyterlab」をインストール。
使いやすいGUI の開発環境です。
PowerShell (またはコマンドプロンプト)で以下を実行。
pip install jupyterlab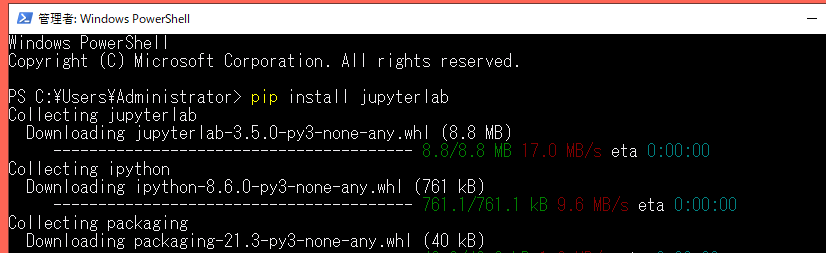
新しいリリースがあるようなので、notice に従って下記も実行しました。
python.exe -m pip install --upgrade pip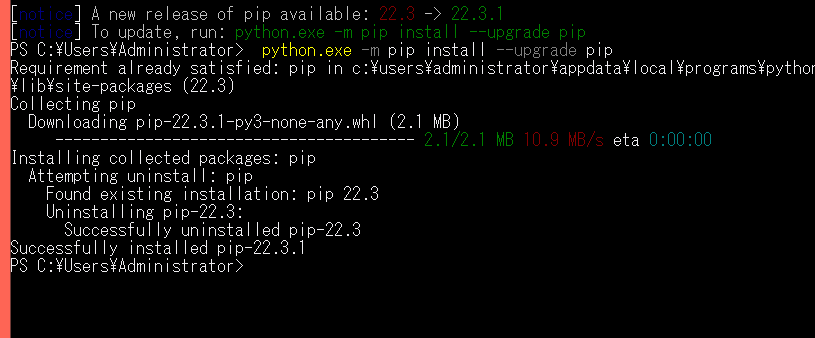
selenium のライブラリをインストール。
pip install selenium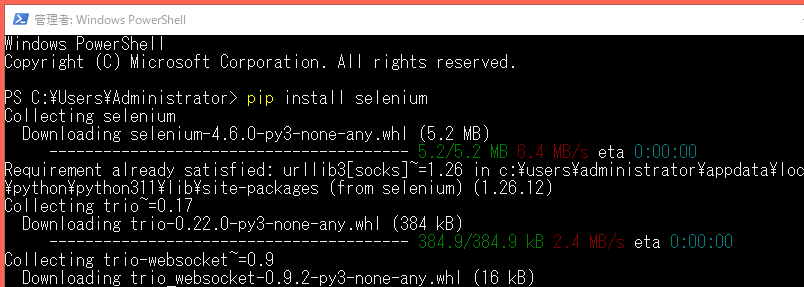
「jupyter lab」を実行。
jupyter lab下図のページが開きます。
Notebook のアイコンをクリックすると、Notebook が開きます。

この行が「セル」と呼ばれるもので、1セル単位で処理を行って実行結果を反映させることができます。
半インタプリタ、みたいな感じです。
解析に使用するブラウザ・エンジンを設定
jupyter でブラウザを使用できる様にするため、ブラウザのドライバーを入手します。
ChromeDriver – WebDriver for Chrome
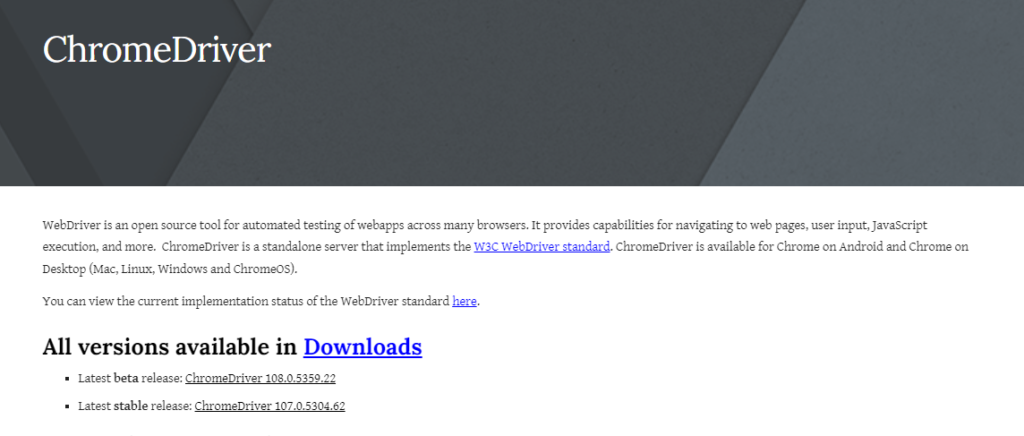
Win32.zip で
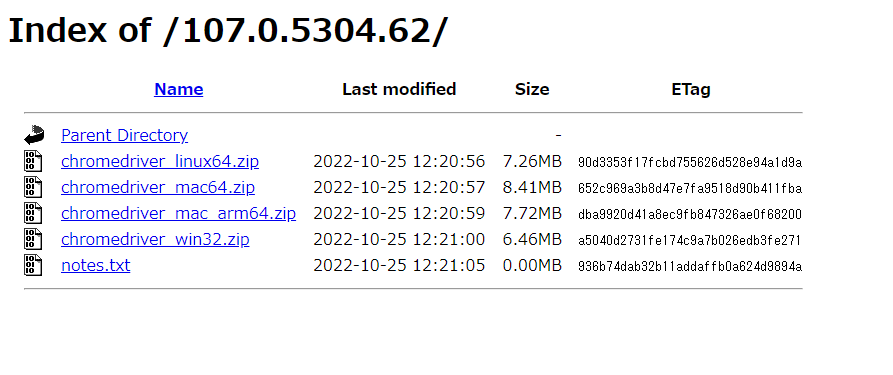
Jupyter のインストールフォルダにでも解凍しておきます。
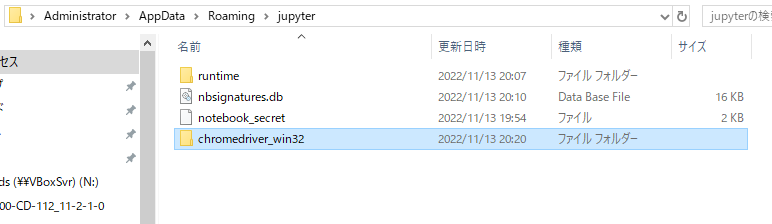
PATH に配置先を指定。
Notebook をクリックし、テキスト欄に下記を入力、【Shift】+【Enter】で実行。
(または、再生マークのアイコンをクリックする。)
from selenium import webdriver
test=webdriver.Chrome()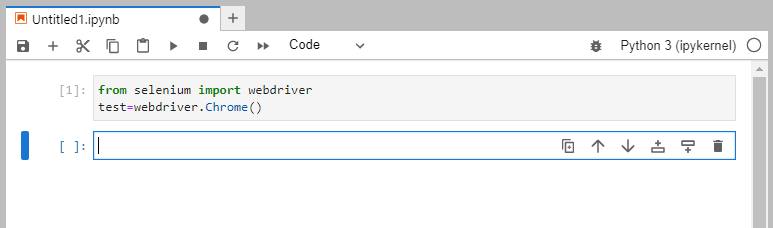
ブラウザが起動されます。
URL を「.get() 」で渡すと、指定したページを開きます。
test.get("https://zapping.beccou.com")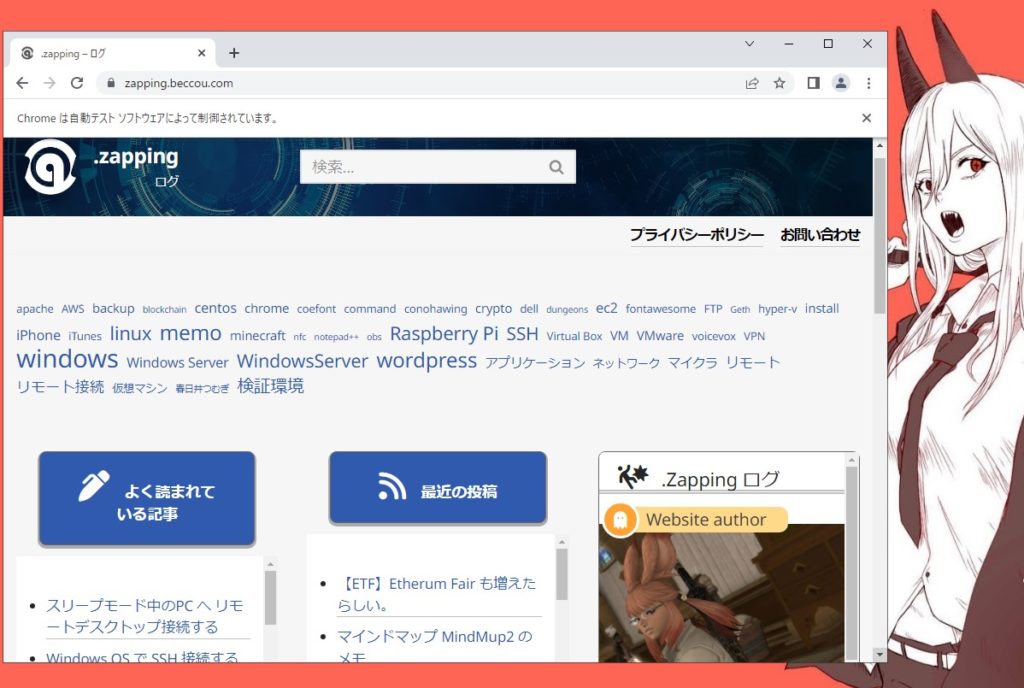
「.quit() 」で閉じます。
使える関数や属性は、ドットを入力したあとにTAB キーを押せばリストが表示されます。
(処理を実行後で具体的に値が入っている状態であれば、その値に対応したメニューが表示されます。)
WEB ページの解析
WEB ページの解析を行っていきます。
Notebook で処理を実行するときにprint() を使って値を確認しています。
また、ブラウザを非表示モードにせず、動作も確認しながら進めています。
イメージ的には、タグ名やクラス名、ID 等を指定してタグを取得し、オブジェクトの様に使用します。
個人的には、HTML ページの要素をJavascript でオブジェクトっぽく指定するのに近い感じと思います。
認証をクリアする
今回は、Basic 認証で、「http://<user_id>:<user_password>@URL」が有効だった。
(直接ブラウザに上記のフォーマットで入力してもダメですが、python からならOK みたいです。)
arg1=test.get("http://wcadmin:******@wc1202.co.jp/Windchill/app/#ptc1/comp/preference.tree?oid=OR%3Awt.inf.container.ExchangeContainer%3A6&u8=1/")ボタンを押下してツリーを展開する。
要素の取得が必要になるのですが、記述の方法がselenium 4 以前のバージョンと、4 以降のバージョンで変わってました。
- selenium 4以前「.find_element_by_xxx(“id”)」
- selenium 4 以降「.find_element(By.id,”id”)」
Selenium Python Bindings – 4. 要素を見つける
これに伴って、4以降のバージョンでは「from selenium.webdriver.common.by import By」による、「By」のインポートも必要。
4.6 なので、「from selenium.webdriver.common.by import By」を追記。
from selenium import webdriver
from selenium.webdriver.common.by import By
test=webdriver.Chrome()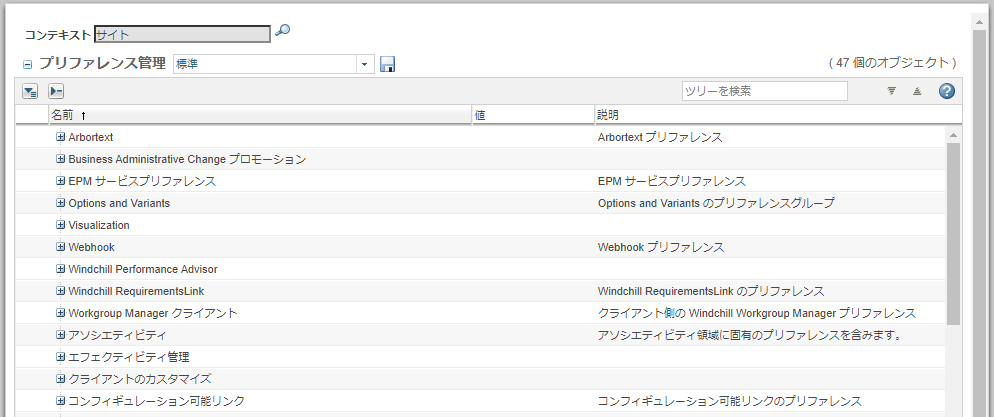
F12 キーを押して開発者ツールを表示し、ボタン要素のID を調べる。
結構トライ アンド エラーで頑張ります。
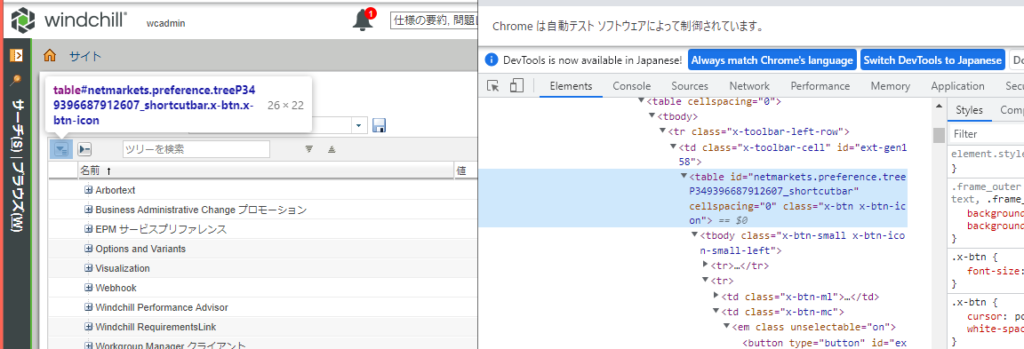
ボタンを取得して、クリックする
arg1=test.find_element(By.ID,"netmarkets.preference.treeP349396687912607_shortcutbar")
arg1.click()ボタンのID が毎回変わるというオニ仕様だったので、結局ID とクラス名で絞り込み取得に変更。
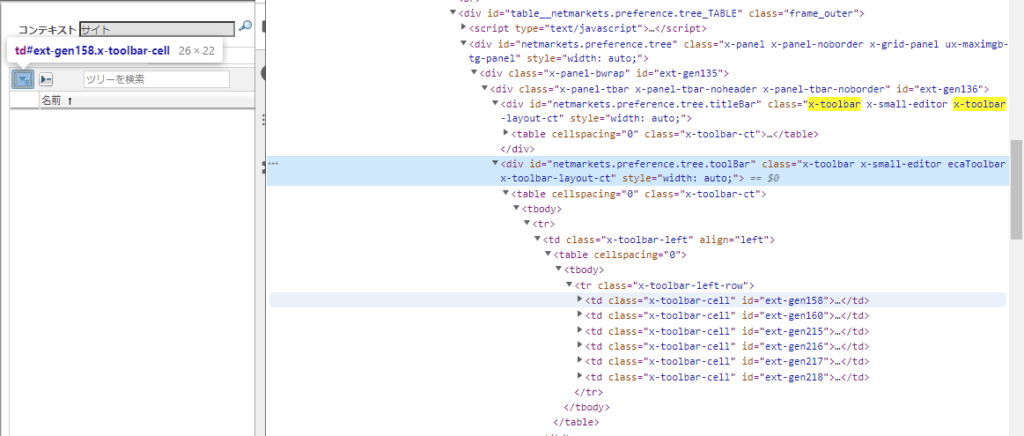
arg1=test.find_element(By.ID,"netmarkets.preference.tree.toolBar")
arg2=arg1.find_element(By.CLASS_NAME,"x-toolbar-cell")
arg2.click()要素から値を取得する
遅延読み込み、読み込み待ちをするときのウェイト操作用のライブラリを追加
from time import sleepfind で要素を指定して読み込み。
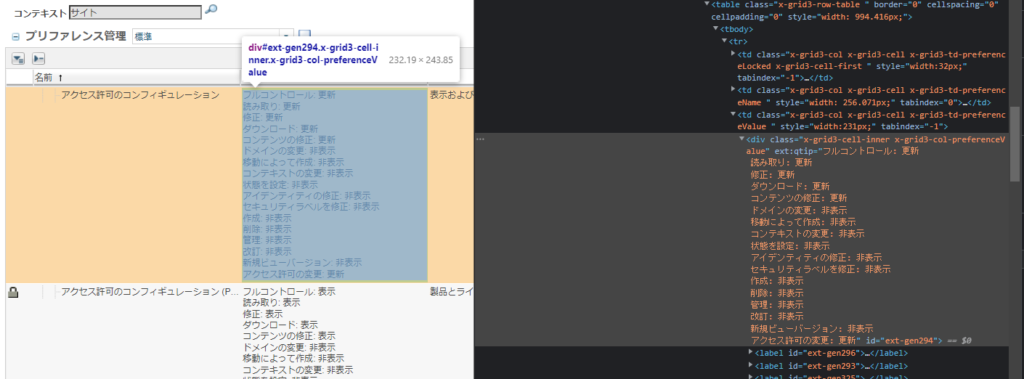
ターゲットページの要素を確認して、データ取得時に何を「キー」にするかを検討。
(開発者ツールでソースを見ると、下記の様なHTML になっていました。)
<table class="x-grid3-row-table " border="0" cellspacing="0" cellpadding="0" style="width:1046.41592920354px">
<tbody>
<tr>
<td class="x-grid3-col x-grid3-cell x-grid3-td-preferenceLocked x-grid3-cell-first " style="width:32px;" tabindex="-1">
<div class="x-grid3-cell-inner x-grid3-col-preferenceLocked">
</div>
</td>
<td class="x-grid3-col x-grid3-cell x-grid3-td-preferenceName " style="width:419.070796460177px;" tabindex="0">
<div class="ux-maximgb-tg-mastercell-wrap">
<div class="x-grid3-cell-name-with-norgie" id="ext-gen318">
<div class="x-grid3-cell-tree-ui">
<div class="ux-maximgb-tg-uiwrap" style="width: 16px">
<div style="left: 1px" class="ux-maximgb-tg-elbow-active ux-maximgb-tg-elbow-minus">
</div>
</div>
</div>
<div class="x-grid3-cell-inner x-grid3-col-preferenceName" ext:qtip="Arbortext">
Arbortext
</div>
</div>
</div>
</td>
<td class="x-grid3-col x-grid3-cell x-grid3-td-preferenceValue " style="width:120px;" tabindex="-1">
<div class="x-grid3-cell-inner x-grid3-col-preferenceValue">
</div>
</td>
<td class="x-grid3-col x-grid3-cell x-grid3-td-preferenceDescription " style="width:459.34513274336285px;" tabindex="-1">
<div class="x-grid3-cell-inner x-grid3-col-preferenceDescription" ext:qtip="Arbortext プリファレンス">
Arbortext プリファレンス
</div>
</td>
<td class="x-grid3-col x-grid3-cell x-grid3-td-stretcher x-grid3-cell-last " style="width:1px;" tabindex="-1">
<div class="x-grid3-cell-inner x-grid3-col-stretcher">
</div>
</td>
</tr>
</tbody>
</table>とりあえず、td タブで取得してみる。
複数あるので、find_elements 、配列で取得する。
arg1=test.find_elements(By.TAG_NAME,"td")
print(arg1[0])
for 文で一覧してみる。
for i in arg1:
print(i.text)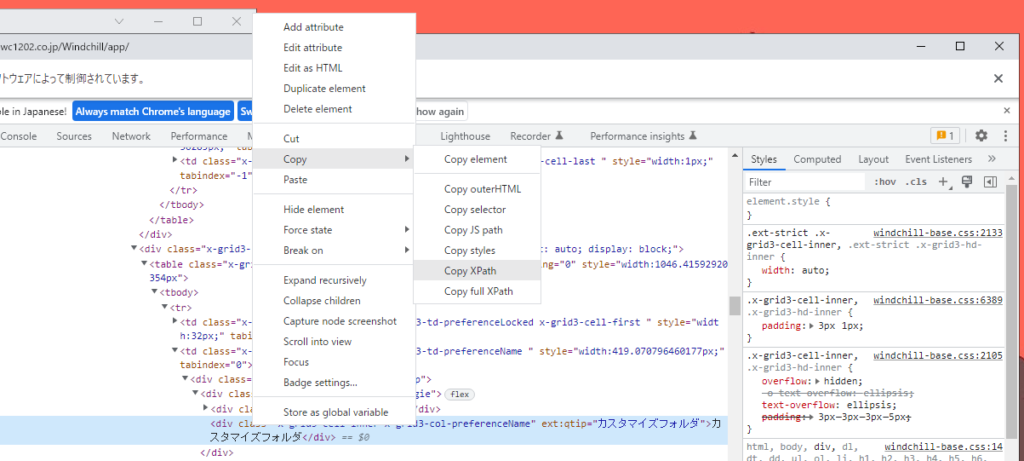
不要な要素も多く取れている為、td タグのdiv タグとして取得する様に変更
arg1=test.find_elements(By.XPATH,'//td/div')さらに親のテーブルを指定して取得できるように。
特定できないので諦め。

2段階で取得して、個別に分けて取得することにした。
tb=test.find_elements(By.XPATH,'//td/div')
arg1=test.find_elements(By.CLASS_NAME,"x-grid3-col-preferenceName")
arg2=test.find_elements(By.CLASS_NAME,"x-grid3-col-preferenceValue")
arg3=test.find_elements(By.CLASS_NAME,"x-grid3-col-preferenceDescription")
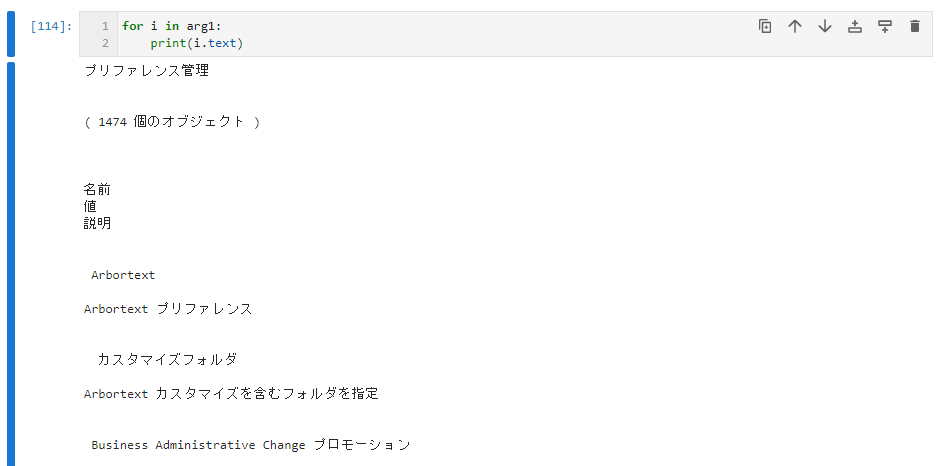
for i in arg1:
print(i.text)取得した3つの配列をFOR 文で結合する。FOR 文でカウンターを使用する場合。
for counter, value in enumerate(r):
print(counter, value.text)for i,value in enumerate(arg1):
print(i,"-->",arg1[i].text,":",arg2[i+1].text,":",arg3[i].text)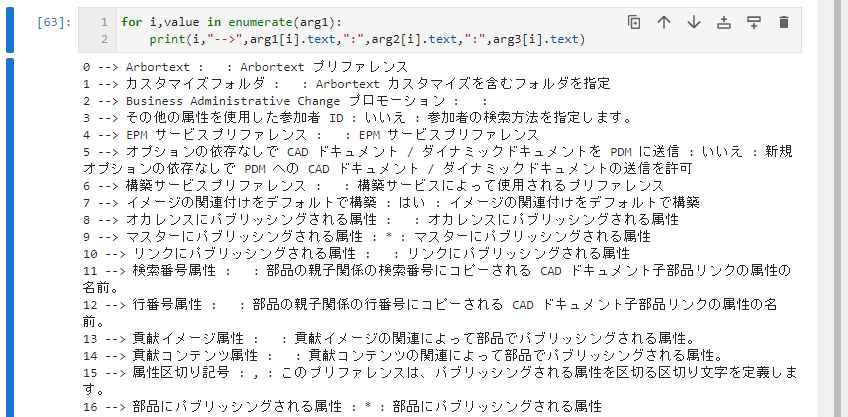
ウエイト処理の追加
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time触れるようになるまで待つ
wait = WebDriverWait(test, 100)
wait.until(EC.element_to_be_clickable((By.CLASS_NAME,"x-toolbar-cell")))
普通に待機するやつ。
import timetime.sleep(10)time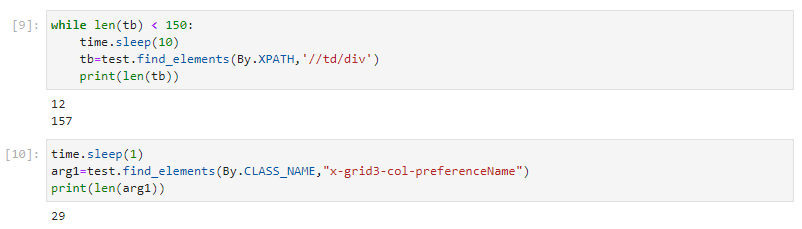
selenium.webdriver.remote.webdriver
スクロールする。
スクロールしないと隠れている部分は読み込まれない。
スクロールし過ぎても読み捨てられてしまう。
1ページくらいずつ、スクロールしながら、読み込みしていきたい。
from selenium.webdriver.common.keys import Keys残念なことにスクロールしなかったので、ドライバに直接スクロールしているから、エレメント指定は要らない。
キーを送信することに。キー送信はエレメントにするので、取得が必要。Body だとうまくできた。
from selenium.webdriver.common.keys import Keysp1=test.find_element(By.TAG_NAME,"body")
p1.click()
p1.send_keys(Keys.PAGE_DOWN)ページ内の値を読み込むくだりから、ループを使って繰り返し処理をつくる。
p1.click()
p1.send_keys(Keys.PAGE_DOWN)
arg_test=["dummy"]
arg1a=arg1
while True:
print("start")
time.sleep(1)
tb=test.find_elements(By.XPATH,'//td/div')
print(len(tb))
time.sleep(1)
arg1a=test.find_elements(By.CLASS_NAME,"x-grid3-col-preferenceName")
print(len(arg1a))
if arg_test == arg1a[0]:
print("BREAK")
break
time.sleep(1)
arg2a=test.find_elements(By.CLASS_NAME,"x-grid3-col-preferenceValue")
print(len(arg2a))
time.sleep(1)
arg3a=test.find_elements(By.CLASS_NAME,"x-grid3-col-preferenceDescription")
print(len(arg3a))
for j,value in enumerate(arg1a):
print(j,"-->",arg1a[j].text,":",arg2a[j].text,":",arg3a[j].text)
arg_test=arg1a[0]
p1.click()
p1.send_keys(Keys.PAGE_DOWN)
print("done")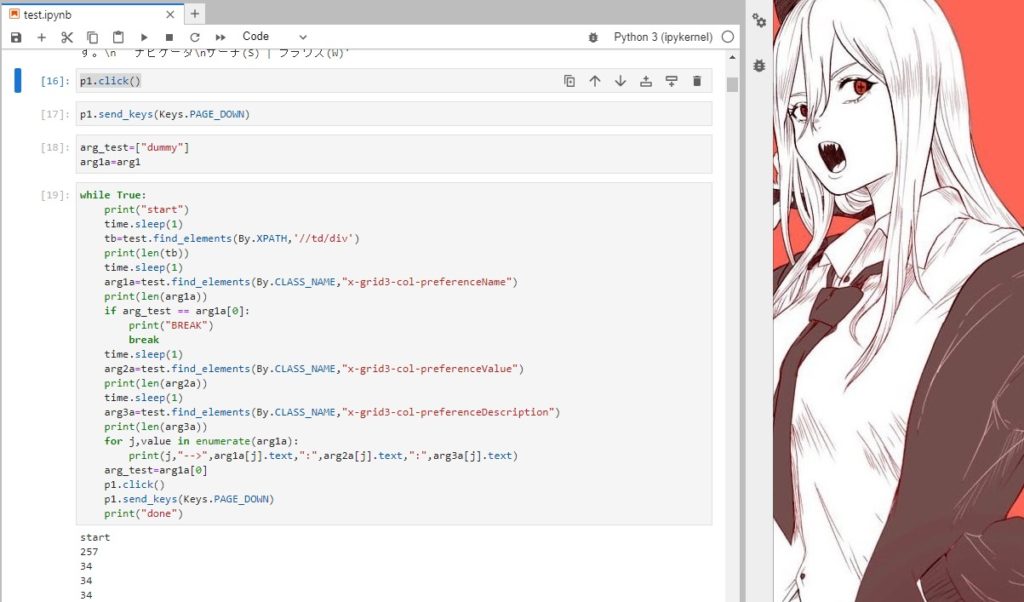
さらに前回の最終データーと出力を比較して、前回のつつきから出力する様にループを修正したのがこれ。
while True:
# init flag
# 1:プリントアウトする 0:しない
printOn=0
# comment
print("start")
# read elements by tag_name --> div
time.sleep(1)
tb=test.find_elements(By.XPATH,'//td/div')
print(len(tb))
# select by class_name
# 1
time.sleep(1)
arg1a=test.find_elements(By.CLASS_NAME,"x-grid3-col-preferenceName")
print(len(arg1a))
# スクロールして変化がないことの確認
# データが変わっていない場合、スクロール完了と判定する
if arg_test == arg1a[0]:
print("BREAK")
break
# 2
time.sleep(1)
arg2a=test.find_elements(By.CLASS_NAME,"x-grid3-col-preferenceValue")
print(len(arg2a))
# 3
time.sleep(1)
arg3a=test.find_elements(By.CLASS_NAME,"x-grid3-col-preferenceDescription")
print(len(arg3a))
# marge lists and output
for j,value in enumerate(arg1a):
newdata=arg1a[j].text+":"+arg2a[j].text+":"+arg3a[j].text
# 直前の最終のデータと比較
if lastdata==newdata:
printOn=1
if printOn==2:
print(j,"-->",arg1a[j].text,":",arg2a[j].text,":",arg3a[j].text)
# 一回見送り後出力するための調整
if printOn == 1:
printOn=2
# set flag
arg_test=arg1a[0]
lastdata=newdata
# scrool...
p1.click()
p1.send_keys(Keys.PAGE_DOWN)
# comment
print("done")カテゴリや小グループ分けの処理
一番簡単なのは、ロケーションを取得して、その値に合わせてインデントを挿入する様にすればいいんじゃないかと。
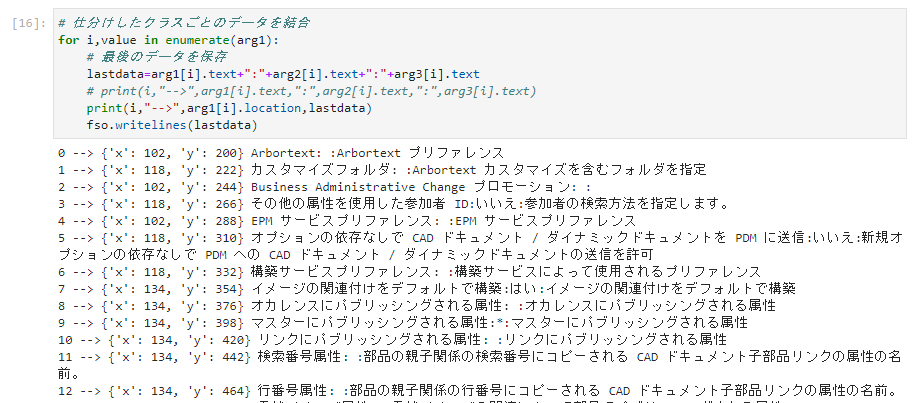
座標データは「.values() →list()」で値として取り出せますと。
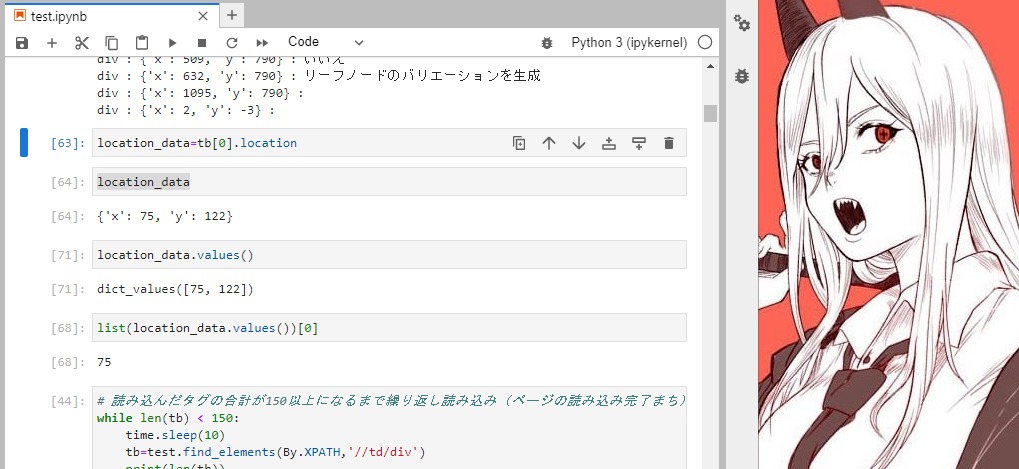
location_data=tb[0].location
list(location_data.values())[0]全部のデータを読み込んでから、インデントの数を決めたいので、
書き出しの直前に処理を追加するのが良いと思い。。。
ってなると格納先は配列にした方がいいか。
X の座標値を書き込むときに同じ値だったら書き込まないようにするところ。
enumerate() は配列だったので、順番に値の比較をする場合は添え字が必要だったお。
こんな感じで、Xの座標値と値のセットを配列に保存。
# 初期化 とりあえず最初の数字を入れておく ※後でソートする。
indent=[(list(arg1[0].location.values())[0])]
# 追加するかしないかのフラグ 0:しない 1:する
add=1
for m in enumerate(indent):
# indent の中に同じ値があったら追加しない
print("if m:",m[1])
if m[1] == x_arg:
add=0
print(add)
# フラグが1なら値を追加
if add==1:
indent.append(x_arg)
print(x_arg)で、こんな感じでインデントにナンバリングします。
for q in enumerate(indent):
indent[q[0]]=[q[1],q[0]+1]
indent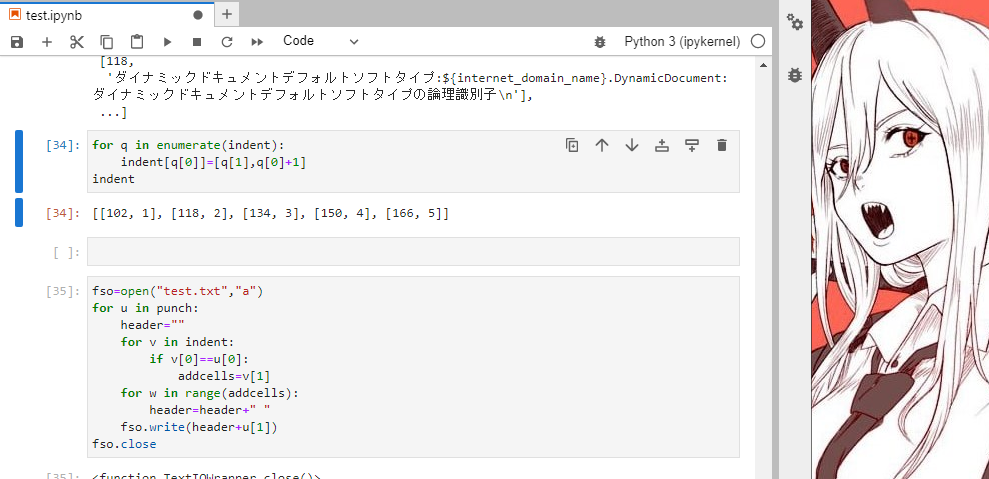
データの取り込み時にX のロケーションも一緒に保存。

あとは書き込みの時にX ロケーションに対応した数の空白を挿入するようにする。
fso=open("test.txt","a")
for u in punch:
header=""
for v in indent:
if v[0]==u[0]:
addcells=v[1]
for w in range(addcells):
header=header+" "
fso.write(header+u[1])
fso.close空白を「セル」として先頭に挿入する場合、その後ろがズレてしまうのでその分の調整も入っているやつ。
list.insert(index,value) で追加しようと思ったけど、
よく考えたら文字列にしているので、テキスト処理だった。
ちょっと記述方法などを確認してみる。
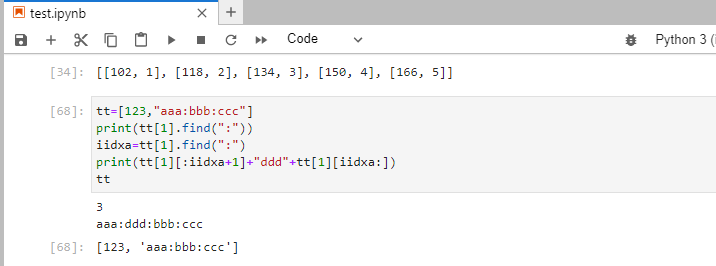
セルの調整処理を追加後
fso=open("test.txt","w")
for u in punch:
header=""
margin=""
for v in indent:
if v[0]==u[0]:
addcells=v[1]
# 先頭に追加する空白
for w in range(addcells):
header=header+":"
# 一番最後のインデントではない場合、配列の2つ目に残りの空白を追加
if len(indent)+1!=addcells:
for y in range(len(indent)-addcells):
margin=margin+":"
iidx1=u[1].find(":")
fso.write(header+u[1][:iidx1+1]+margin+u[1][iidx1:])
print(header+u[1][:iidx1+1]+margin+u[1][iidx1:])
else:
fso.write(header+u[1])
print(header+u[1])
fso.close()コロンを区切り文字にしていると、たまにコロンが含まれている文字列で区切られてしまう。
そういう場合は区切り文字を変更して対応する。
もうね、変数にした。
書き出し処理の追加

fso=open("test.txt","w+")
fso.fso.writelines("Strings")
fso.close()これだけでとりあえず、テキストへの書き出しができるのは便利ですよね。
ちなみにwriteline() を使っても改行が入るわけではなかったっす。
改行したい場合は、文字列の最後に「\n」を挿入します。
書き込み内容を変数で保存して置いて、最後にまとめて書き出し処理しないと読み込み時間がけっこう増える。
改行の問題
改行が入っているデータでセルがずれている。

repr() で改行を文字列として取れた。
(シングルコーテーションで括った状態のデータになりました。)
lastdata=arg1[i].text+":"+repr(arg2[i].text)+":"+arg3[i].text
Pythonで改行を含む文字列の出力、連結、分割、削除、置換